ImageInThat: Manipulating Images to
Convey User Instructions to Robots
HRI 2025
1 University of Toronto, 2 Singapore Management University, 3 University of Wisconsin-Madison




Foundation models are rapidly improving the capability of robots in performing everyday tasks autonomously such as meal preparation, yet robots will still need to be instructed by humans due to model performance, the difficulty of capturing user preferences, and the need for user agency. Robots can be instructed using various methods—natural language conveys immediate instructions but can be abstract or ambiguous, whereas end-user programming supports longer-horizon tasks but interfaces face difficulties in capturing user intent. In this work, we propose using direct manipulation of images as an alternative paradigm to instruct robots, and introduce a specific instantiation called ImageInThat which allows users to perform direct manipulation on images in a timeline-style interface to generate robot instructions. Through a user study, we demonstrate the efficacy of ImageInThat to instruct robots in kitchen manipulation tasks, comparing it to a text-based natural language instruction method. The results show that participants were faster with ImageInThat and preferred to use it over the text-based method.
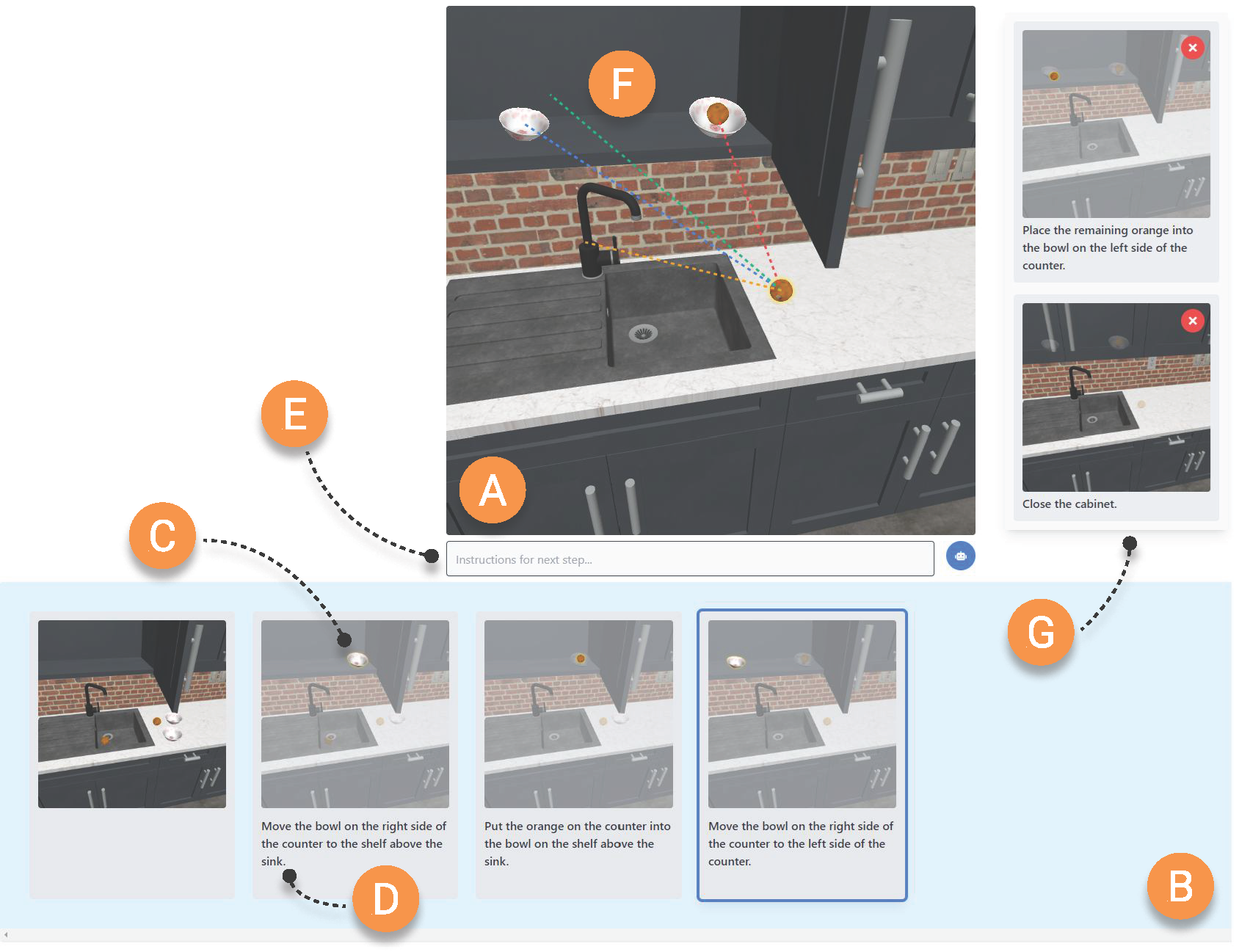
In ImageInThat, the robot's environment is processed to create an internal representation consisting of knowledge about objects and fixtures. Objects are items that can be manipulated from one location to another (e.g., bowls that need washing) whereas fixtures are items that are immovable. Both objects and fixtures can be in more than one state; for example, a cabinet is a fixture that can be open or closed. ImageInThat includes an editor that utilizes this internal representation. The editor consists of a timeline-style interface where users can manipulate images to generate robot instructions. For instance, users can drag an object from one location to another to generate a pick-and-place instruction. Users can also manipulate fixture states, such as by clicking a cabinet to open or close it. Along the way, each change appears as a step in the timeline. ImageInThat also includes features to visualize changes between steps inside the timeline. This includes visual filters on each step to highlight changes, and a comparison view that shows the differences between two steps. ImageInThat also includes experimental features to allows users to blend language with image to create instructions rather than relying solely on image manipulation. ImageInThat can also provide some assistance to the user in specifying the location of a selected object through manipulation-level auto-completion. Or, the user can click a button to request an image representing possible future states of the environment.
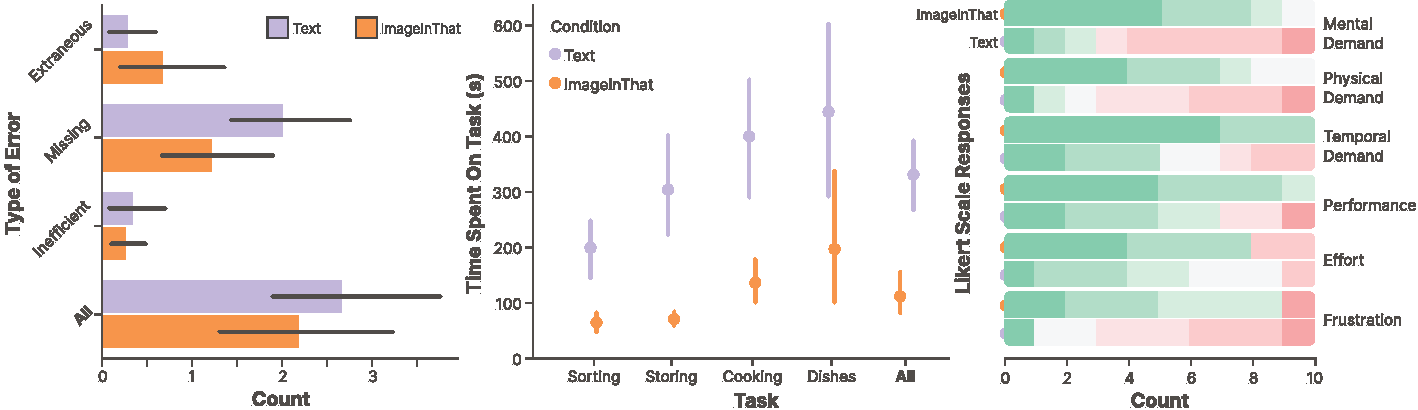
We evaluated ImageInThat in a user study where participants were asked to instruct a robot in simulated kitchen manipulation tasks. Participants were asked to perform the tasks using both ImageInThat and a text-based natural language instruction baseline.

We found that participants were faster with ImageInThat than with the text-based method across all tasks. However, we noticed that participants made different types of errors with ImageInThat compared to the text-based method. For instance, participants added extraneous steps in ImageInThat, which could be due to the low-cost nature of adding steps in ImageInThat. In contrast, participants missed more steps in the text-based method, which could be due to the difficulty in keeping track of the steps in the text-based method.
We experimented with image-to-code translation as a method to convert the manipulated images into robot instructions. We prompted an LLM with the skill primitives: pick, place, grasp, ungrasp, turn on faucet, turn off faucet, and stack object, and the manipulated images. The LLM then generated code that could be executed by the robot to perform the task. We evaluated four translation tasks. The first task required the robot to put a red apple into a white bowl in a table featuring a bowl, two green apples and a red apple. Here, the translation was successful 10 out of 10 times. The second task required the robot to put both green applies into the white bowl and the red apple into the bowl with the pattern. This translation was also successful 10 out of 10 times. The third task required the robot to put a bowl in the sink, place an orange inside it, and wash the fruit by turning on the faucet. This task was successful 8 out of 10 times, but in 6 runs the translation incorrectly moved the second orange into the second bowl as well though without moving it to the sink or washing it. In the fourth task, we used part of the fourth evaluation task whereby the robot needed to stack the orange donut on the plate containing the pink donut. The translation succeeded 7 out of 10 times, but in 3 runs, it mistakenly included code to rearrange spoons.
Below is an interactive demo of ImageInThat. You can try instructing a robot by directly manipulating visual elements of the scene. This demo uses preprocessed data and runs fully in the browser. However, without the server side, many features are not available, including captioning of steps and autocomplete.